按排障和运维场景整理常用 Linux 命令,优先保留能直接定位问题的内容。
查看系统芯片方案
cat /proc/cpuinfo dmesg 日志
openwrt 编译时需要选择系统类型用
能看到 系统类型 是MT7620A,上面的machine参数给的是自己的固件命名。
root@IceCreamBox:~# cat /proc/cpuinfo
system type : Ralink MT7620A ver:2 eco:3
machine : IceCreamBox
processor : 0
cpu model : MIPS 24KEc V5.0
BogoMIPS : 385.84
wait instruction : yes
microsecond timers : yes
tlb_entries : 32
extra interrupt vector : yes
hardware watchpoint : yes, count: 4, address/irw mask: [0x0ffc, 0x0ffc, 0x0ffb, 0x0ffb]
isa : mips1 mips2 mips32r1 mips32r2
ASEs implemented : mips16 dsp
shadow register sets : 1
kscratch registers : 0
core : 0
VCED exceptions : not available
VCEI exceptions : not available
二进制显示文件 linux
od -tx1 -tc -Ax binFile
常用操作
grep
grep -aiI ‘recv packet’ .log 避免将文件输出为二进制 -a
mount
挂载前先用 mount | grep <mountpoint> 确认目标是否已挂载。
umount -l /dev/mmcblk0p1 可用于延迟卸载。
dmesg
unix_time=echo "$(date +%s) - $(cat /proc/uptime | cut -f 1 -d' ') + 12106473.374733" | bc
输出结果 s 转换为 unix时间
strace 系统函数trace
/usr/bin/strace -o output2.txt -T -tt -e trace=all ./chat
/usr/bin/strace -tt -T -v -f -e trace=file -o strace1.log -s 1024 ./chat
/usr/bin/strace -tt -T -v -f -e trace=file -o strace1.log -s 1024 -p pid #### ltrace 库函数trace
pstack gstack
proc
/proc/N/fd /proc/net/tcp
以上2个,配合使用可以定位 socket fd的连接。
/proc/locks /proc/cmdline
清理线上大文件,先设置低优先级,再删除
考虑到对线上服务 IO 造成的影响,应该将大文件 mv 走之后,设置操作为低优先级再执行 mv … && cd .. && nice -n 6 “${command}”
awk-1
cat 2.log | awk -F” “ ‘{print $1” “ $2” “ $3” “ $4}’ | sort -t’ ‘ -k4 -rn
awk-2 统计log行数
grep '2022-07-25 10:' service.log.2022072510 | awk -F' ' '{print $6}' | sort | uniq -c #### find find . -type f \(-name "*.cpp" -o -name "*.h" \) | xargs -P 4 grep -i NoNeedTo --col
IO 查询命令
iostat iotop lsof /dev/sda | grep head cat /proc/$id/io pidstat -d 1
CPU使用率低但是负载高
当系统负载高时,并不意味着CPU资源不足,只是意味着运行的任务过多,这些任务有可能在等待或者使用cpu,也有可能等待IO完成
当系统负载高,并且CPU使用率也比较高时,一般意味着CPU资源不足
而当系统负载高,而CPU使用率比较低时,一般有如下两种情况
CPU频繁的进行上下文切换(比如应用中开启了太多的线程),导致任务执行的时间比较短(利用vmstat命令查看,如果cs列或in列的值很大,说明就是这种情况)
IO任务太多,导致大量进程处于不可中断状态(利用top命令查看,cpu使用百分比中,wa状态(cpu等待io完成)的使用百分比很高时,说明就是这种情况)
执行vmstat,查看in列(每秒中断的次数)和cs列(每秒上下文切换次数)比较高,则表明CPU频繁的进行上下文切换
top发现cpu的iowait比较高(wa列的值),则利用I/0问题排查套路接着排查
如果我们希望对特定的进程进行监控,可以使用pidstat -w命令
pidstat是sysstat工具的一个命令,用于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况
pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息
# 每隔3s输出一次数据
[root@VM-0-14-centos ~]# pidstat -w 3
Linux 3.10.0-1127.19.1.el7.x86_64 (VM-0-14-centos) 10/10/2021 _x86_64_ (2 CPU)
08:13:38 PM UID PID cswch/s nvcswch/s Command
08:13:41 PM 0 6 1.66 0.00 ksoftirqd/0
08:13:41 PM 0 7 0.33 0.00 migration/0
08:13:41 PM 0 9 20.27 0.00 rcu_sched
结果中的cswch和nvcswch是我们需要重点关注的对象
cswch(自愿上下文切换):进程无法获取所需要的资源,导致的上下文切换。例如IO,内存等系统资源不足时,就会发生自愿上下文切换 nvcswch(非自愿上下文切换):进程由于时间片已到等愿意,被系统强制调度,进而发生的上下文切换。比如,当大量进程都在争抢CPU时,就容易发生非自愿上下文切换
复制整个文件夹(使用r switch 并且指定目录)
3-1 从本地文件复制整个文件夹到远程主机上(文件夹. 假如是diff) 先进入本地目录下,然后运行如下命令: scp -v -r diff root@192.168.1.104:/usr/local/nginx/html/websroot@192.168.1.104:/usr/local/nginx/html/webs
3-2 从远程主机复制整个文件夹到本地目录下(文件夹假如是diff) 先进入本地目录下,然后运行如下命令: scp -r root@192.168.1.104:/usr/local/nginx/html/webs/diff .
perf
每s采集99次,-p pid perf record -F99 -g -a -e cpu-clock -p 23801 perf report -i perf.data
top
top 重要:各个参数的含义, 系统cpu使用率, 业务CPU使用率,swap等
[linux的top参数含义详解]https://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316399.html
查看线程cpu使用率
[线程cpu使用率]https://www.cnblogs.com/ghost240/p/3863774.html
查看进程线程数量
ps -T -p ${pid}
ps -T -H ${pid}
ip 正则
ip grep
grep -E “[^^][0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}”
grep -oE “[^^][0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}” 3.log –col
xargs 执行shell
cat 2.txt | xargs -I {} sh -c {} 或者 -i 如果-I报错的话。 #### scp scp output/bin/test {user}@{host}:{path} scp -v -r yun_conf {user}@{host}:{path} #### 使用gcore 最初统计的时候,发现CPU高的情况会出现1秒多的时间,如果发现CPU高负载时,直接调用gcore {pid}的命令,可以保留堆栈信息,明确具体高负载的位置。
将使用gcore的指令,添加到统计工具中取,设置CPU上门限触发。
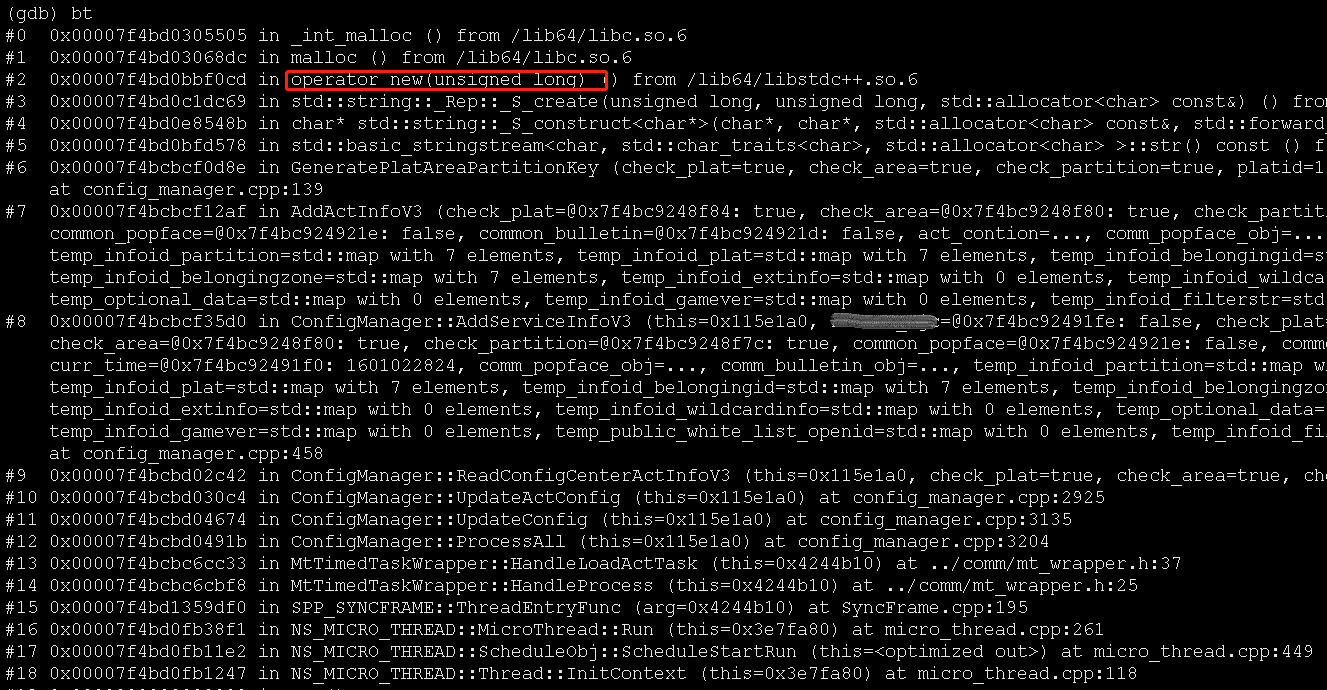
通过gdb看了几个coredump文件,发现堆栈和函数调用基本一致。可以明确的看到,大量的耗时发生在了AddActInfoV3这一函数中:
vmtouch
查看linux文件的pagecache情况-vmtouch
vmtouch - the Virtual Memory Toucher 就是用来查看linux文件缓存(page cache)使用情况,命中率
线上高负载时,page cache 过多只是可能原因之一。可以先用 vmtouch 判断哪些文件占用了较多 page cache,再结合业务影响决定是否处理;echo 3 > /proc/sys/vm/drop_caches 属于高影响操作,只应在确认风险、评估业务影响后再执行。
合并txt文件
ls *.txt |
while read file_name;
do
# 用.为分隔符只要文件名,去掉文件后缀
cat "$file_name" >> all.txt
echo "" >> all.txt
done
查看符号
nm bin文件
查看依赖的so文件
ldd bin文件
ssh + rsync 互传文件,rsync断点续传
Start port forwarding backend
ssh -f -N -L 1234:HostC:22 user@HostB
# You can
# 1. Either, login HostC from port 1234 on localhost
ssh -p 1234 user@localhost
# 2. OR, scp directly
scp -P 1234 src_dir/ user@localhost:target_dir/
# upload
rsync -P --rsh='ssh -p 1234' /data/myfile user@localhost:/data/
# download
rsync -P --rsh='ssh -p 1234' user@localhost:/data/myfile /data/
查看cpu核数
grep 'model name' /proc/cpuinfo | wc -l
cpu密集型进程/IO密集型进程/大量等待cpu调度进程均会导致负载高,但是IO密集型进程不会导致cpu利用率高
sysstat包含常用性能工具,其中 mpstat 和 pidstat 分别查看cpu利用率和进程占用情况的工具 , vmstat 分析系统性能的工具
# -P ALL 表示监控所有cpu,后面的数字5表示间隔5s输出一组数据
mpstat -P ALL 5
节点负载高的排查方法
uptime 查看负载变化情况 通过 mpstat 查看cpu计算量大还是进程争抢大或者io过多
iowait表示等待io多,cpu表示cpu本身的消耗,根据 二者数值可以判断是计算密集型还是io密集型。
查看进程负载高
# 间隔5s输出一组数据,只输出一次
pidstat -u 5 1
如果,cpu高,iowait低,说明是纯计算密集型;如果cpu低,iowait高,纯io密集型,io包含网络io,磁盘io。二者都高,可以继续查看队列情况,上下文切换次数和类型进一步判断。
查看整体的上下文切换情况及队列长度,队列长度大于核数说明负载高。
每隔5s输出1组数据
vmstat 5
# r 表示就绪队列长度
# cs 表示上下文切换次数
# in 表示每s中断次数
# b 表示处于不可中断睡眠状态的进程数
查看每个进程的上下文切换种类
# 每隔5s输出一组数据
pidstat -w 5
#cswch 进程每s自愿上下文切换次数,说明进程都在等其他资源,如io
#nvswch 进程每s非资源上下文切换次数,等待线程过多
#自愿 一般情况下在资源不足,无法获取资源的情况下出现,非自愿 一般在大量线程进行cpu争用的时候出现
#pidstat 默认展示进程数据, 增加-t 参数显示线程数据
###
ls -l 4472_gid | awk -F' ' '{print $9}' | xargs -i sh -c 'cat 4472_gid/{}' | xargs -i sh -c 'echo -n {} " "; echo "get ig_{}" | ../redis-cli -h ip -p 9000;' | grep 4472 >> new_t.txt &
ssh 连接iot设备
ssh -oHostKeyAlgorithms=+ssh-dss root@192.168.8.109
shell 修改默认bash dash
linux top 10 检查命令
当你登录到一台存在性能问题的Linux服务器上时,在头一分钟,你会检查什么?
我们看看Netflix的性能工程师是怎么做的。
Netflix大量使用EC2 Linux服务器,很多时候是用一些较为高层的工具做云或实例层次的分析。不过有时仍然需要登录到某个实例上,运行一些标准的Linux性能工具。
在最开始的一分钟内,可以先利用手头的标准Linux工具大致了解性能状况。借助如下10条命令(有些命令需要安装sysstat包),了解系统资源使用状况和正在运行的进程。先检查错误(errors)和饱和度(saturation),再检查资源利用率(resource utilization)。饱和度指的是负载已经超过处理能力,像请求队列的长度,等待时间等。
uptime
dmesg | tail
vmstat 1
mpstat -P ALL 1
pidstat 1
iostat -xz 1
free -m
sar -n DEV 1
sar -n TCP,ETCP 1
top
这里要提一下定位性能瓶颈的USE方法。在Brendan Gregg的《System Performance: Enterprise and the Cloud》(中译本:《性能之巅:洞悉系统、企业与云计算》)一书中有具体的描述。
如果手头有这本书的中译本,可以看一下36页:
USE方法(utilization、utilization、errors)应用于性能研究,用来识别系统瓶颈。一言以蔽之,就是:
对于所有的资源,查看它的使用率、饱和度和错误。
这些术语定义如下。
资源:所有服务器物理元器件(CPU、总线……)。某些软件资源也能算在内,提供有用的指标。
使用率:在规定的时间间隔内,资源用于服务工作的时间百分比。虽然资源繁忙,但是资源还有能力接受更多的工作,不能接受更多工作的程度被视为饱和度。
饱和度:资源不能再服务更多额外工作的程度,通常有等待队列。
错误:错误事件的个数。
……
USE方法会将分析引导到一定数量的关键指标上,这样可以尽快地核实所有的系统资源。在此之后,如果还没有找到问题,那么可以考虑采用其他的方法。
下面具体看一下这10条命令。
uptime
快速查看平均负载(任务对CPU资源的需求)。输出中的“load average:”后面的三个数字,是系统在1分钟、5分钟和15分钟内的平均负载。表示负载随时间的变化情况。
它给出的只是一个较为高层的情况,往往需要借助其他工具进一步确认性能问题,有时候需要通过其他一些指标来了解CPU负载,例如vmstat或mpstat。
2. dmesg | tail
查看最后10条系统消息。查找可能会引发性能问题的错误。千万不要漏掉这一步。
3. vmstat 1
统计虚拟内存信息。参数1指的是打印1秒内的统计信息。
要检查的列:
r:运行队列的长度(这个参数的解释,建议参考《性能之巅》一书)。可以更好地确定CPU的饱和度。“r”值大于CPU数则为饱和。
free:以kb为单位的空闲内存。如果这个值很大,说明有足够的空闲内存。下面将介绍的第7条命令——“free -m”,可以更好地解释空闲内存的状态。
si, so:换入的内存和换出的内存。如果它们不为0,说明内存已经耗尽。
us, sy, id, wa, st:CPU时间的不同组成部分,是所有CPU的平均数。分别表示用户态时间、系统态时间(内核)、空闲、等待I/O以及窃取时间(stolen time,虚拟化环境下,CPU在其他租户上的开销)。
将用户态时间和系统态时间相加,可以判断CPU是否忙碌。如果一直有等待I/O,表明存在磁盘瓶颈。因为任务阻塞等待磁盘I/O,此时CPU是空闲的。可以将等待I/O看作另一种形式的CPU空闲。
I/O处理一定会消耗系统态时间。如果系统时间平均占比很高,比如说超过20%,或许可以深入研究一下:可能是内核处理I/O的效率不高。
4. mpstat -P ALL 1
打印每个CPU的状况。可以检查各CPU的负载是否均衡。比如,如果一个CPU很热,可能是单线程应用造成的。
5. pidstat 1
pidstat按进程打印CPU的使用情况。循环输出活动进程的信息。可用于观察模式随时间的变化情况。用户也可以把观察到的信息记录下来,以供分析研究。
像图中的例子,可以看到有2个Java进程消耗了大部分CPU时间。“%CPU”这一列是所有CPU的整体情况,“1591%”这个值表明这2个Java进程几乎占用了16个CPU。
6. iostat -xz 1
这是了解块设备的一个极佳工具,能看到实际负载和性能信息。
r/s, w/s, rkB/s, wkB/s:分别表示每秒发给磁盘设备的读请求数,每秒发给磁盘设备的写请求数,每秒从磁盘设备读取的KB数,每秒向磁盘设备写入的KB数。可以使用它们表示负载特性。性能问题可能就是由过多的负载造成的。
await:平均I/O响应时间,单位为毫秒。包括排队时间和服务时间。如果它大于预期的平均时间,可能是设备已经饱和,也可能是设备存在问题。
avgqu-sz:提交到设备的平均请求数。如果大于1,设备可能已经饱和。
%util:设备使用率。设备忙于处理请求的百分比。如果大于60%,通常会导致较差的性能(可以在await中看出来),不过也与具体的设备有关。如果接近100%,通常意味着设备已经饱和。
如果存储设备是后面有多块磁盘支撑的逻辑磁盘,即使设备使用率是100%,后端磁盘也可能远没有饱和,而是还能处理更多工作。
7. free -m
主要看最右边的两列:
buffers:用于块设备I/O的缓冲区高速缓存的大小。
cached:文件系统使用的页缓存大小。
我们只需要检查这两个值,如果它们接近0,则会导致更高的磁盘I/O(可以使用iostat确认),性能更糟。图中的例子,这个状况看上去还不错。
8. sar -n DEV 1
使用该工具检查网络接口的吞吐量,以rxkB/s和txkB/s为手段测量负载。
9. sar -n TCP,ETCP 1
这是一些关键TCP指标的总结。其中包括:
active/s:每秒本地发起的TCP连接数(比如通过connect())。
passive/s:每秒远端发起的TCP连接数(比如通过accept())。
retrans/s:每秒TCP重传数。
active和passive连接数通常用于粗略地测量服务器负载。方便起见,可以把active看作向外的连接,把passive看作向内的连接;不过也有不严格之处,比如考虑从localhost到localhost的连接。
重传数是网络或服务器问题的一个信号:可能是网络不可靠;也可能是服务器过载和丢包。像图中的例子,每秒只有一个新的TCP连接。
10. top
top命令包含很多前面检查过的指标。可以用个命令来检查是不是有指标和之前命令的输出差距很大。
top命令有个缺点,很难看出某个指标随时间的变化模式,这种情况下用像vmstat和pidstat这样的命令可能更清楚,它们能提供滚动输出。间歇性问题的一些迹象,如果不能足够快地暂停输出(Ctrl-S暂停,Ctrl-Q继续),可能会错过。
ubuntu rm回收站功能
vi ~/.bashrc
# 参数说明:
# -t参数表示target-directory,指定到了unbutu系统默认回收站目录~/.local/share/Trash/file
# --backup=t表示使用后缀数字的方式区分rm同名文件的版本
alias rm='mv -t ~/.local/share/Trash/files --backup=t'
source ~/.bashrc
vmware 虚拟机 network unplugable
虚拟网络编辑器 重置
多线程 grep
find . -type f -regextype posix-extended \
-regex '.*/[0-9]{6}\..*' \
-printf "%p\n" | \
awk -F/ '{n=substr($3,1,6); print n " " $0}' | \
sort -k1,1 | \
cut -d' ' -f2- | xargs -P 4 grep -i -E 'ArmMoveObjsTo|ArmGraspObject|ArmHelper|ArmController' --color
sudo:/usr/bin/sudo 必须属于用户 ID 0(的用户)并且设置 setuid 位
U盘进入 grub 模式
如何进入recovery mode, 在适当的时机,长按 hp shift + f11(grub) shift + f10 shift+ f12(network boot)?!!! 也有说 多点 esc的,碰到的是前边这个
一、前言
这是一个神奇的错误,缘由是因为有人将/usr/bin/sudo的权限改为777或其他。
解决办法:最终目的只有一个,想办法执行chmod 4755 /usr/bin/sudo 和 chmod 755 /usr 语句
二、解决办法
1.如果知道root密码。
su登录root用户,执行命令chmod 4755 /usr/bin/sudo 执行命令chmod 755 /usr
2.不知道root密码。
重启机器,ubuntu下按esc或shift,进入recovery模式(即单人模式),进入后选择root选项,有的会提示输入root密码。
(1).不需要输入root密码的情况下,执行如下两条命令。
chmod 4755 /usr/bin/sudo
chmod 755 /usr
(2)需要输入root密码的难兄难弟们,请往下看。
重启的时候,进入ubuntu高级选项(有的系统是英文的,自己翻译,大概是Advanced options for ubuntu这样),之后能看到recovery 啥啥啥的,按e进入,找到linux /boot/vmlinuz-----\*** ro recovery nomodestset 这句话。
然后将ro recovery nomodestset啥啥啥一大串修改为 rw single init=/bin/bash,然后ctrl+x进入单人模式。
(此时,想要更改root密码的输入passwd <密码>,之后再确认一次就更改成功了。)执行如下命令。
chmod 755 /usr
chmod 4755 /usr/bin/sudo
然后重启查看。
三、题外
如果重启之后,提示sudo:在加载插件“sudoers_policy”时在 /etc/sudo.conf 第 0 行出错。
必须用root登录(如果不知道密码,用第2点第2条进行重置root密码),卸载sudo并重装就可以了。
ubuntu命令如下:apt-get remove sudo 执行apt-get install sudo。