开启 core dump 前先确认磁盘空间、权限和落盘目录。生产环境不要无脑全局开启
unlimited,否则连续崩溃时可能把磁盘写满。
先开启 core dump
当前 shell 临时开启:
ulimit -c unlimited
临时指定 core 文件命名规则:
sudo sysctl -w kernel.core_pattern=/tmp/core-%e-%p-%t
不要直接把 core_pattern 指向业务二进制目录或 root 私有目录,除非你已经确认对应服务账户有写权限、目录可清理,而且不会把敏感数据长期留在错误位置。需要持久化时,优先写入 /etc/sysctl.d/*.conf 后再 sysctl --system。
方法 1:dmesg + addr2line
适合先快速确认大致崩溃位置。
-
带调试信息编译程序:
gcc -g -o taogeSeg taogeSeg.c -
运行后查看内核日志中的崩溃地址:
dmesg | grep taogeSeg -
用
addr2line把地址转换到源码行号:addr2line -e taogeSeg 0x080483c9
如果系统开启了 dmesg_restrict,普通用户可能看不到完整日志,这时更适合直接拿 core 文件进 gdb。
方法 2:strace + addr2line
当程序在崩溃前会进行复杂的文件、网络或进程调用时,strace 能帮助你看到最后几个系统调用,再配合 addr2line 缩小范围。
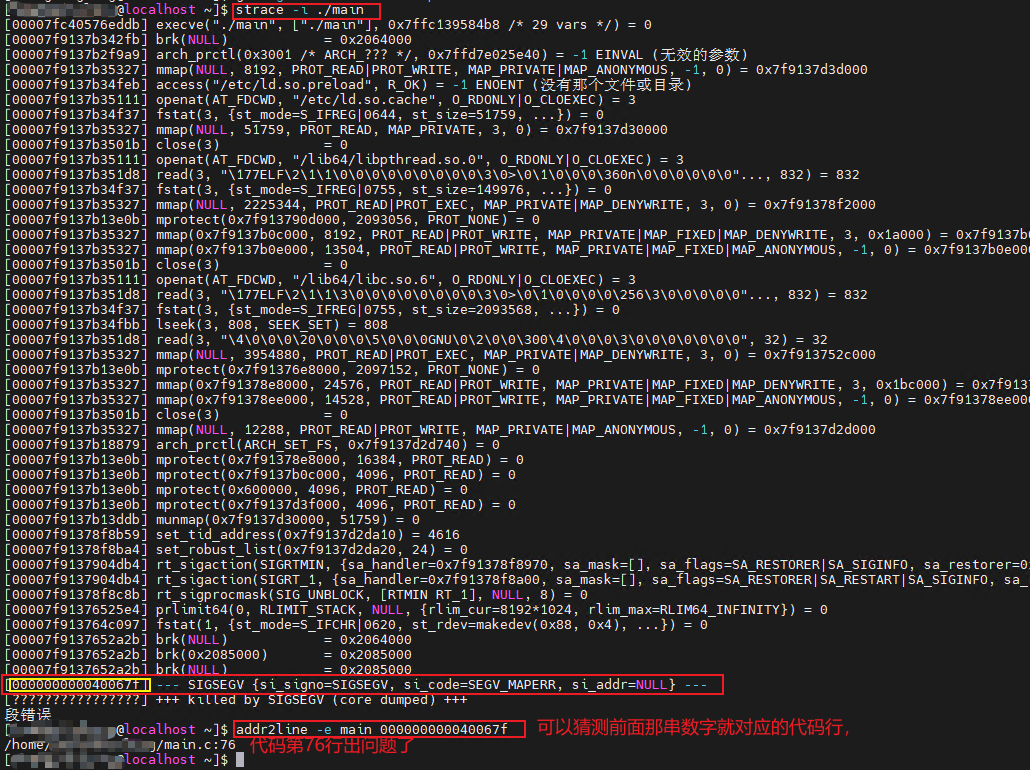
方法 3:日志 + 二分缩小范围
如果没有稳定复现的 core 文件,最实用的仍然是:
- 补充关键路径日志
- 对可疑逻辑做二分开关
- 缩小到最小复现输入
很多线上崩溃最终并不是靠“单步调试”解决,而是靠复现条件和日志上下文定位出来的。
方法 4:直接用 gdb 分析 core
gdb /path/to/program /path/to/core-file
进入 gdb 后常用命令:
bt
frame 0
info locals
info args
thread apply all bt
如果变量因为编译优化被折叠,可以结合这篇资料排查:
https://www.qdcto.com/archives/1002#_%E6%9F%A5%E7%9C%8B%E8%A2%AB%E4%BC%98%E5%8C%96%E5%90%8E%E7%9A%84%E5%8F%98%E9%87%8F%E5%80%BC
方法 5:反汇编当前函数
在 gdb 里查看当前函数的反汇编:
disassemble proc_conn_timeout_limited
disassemble /m proc_conn_timeout_limited
/m 会把源码和汇编混排显示,适合排查优化后的代码路径。
方法 6:查看寄存器
info registers
当崩溃点涉及空指针、非法地址访问或调用约定问题时,寄存器值往往能直接提示是哪一个参数出了问题。
FEATURED TAGS
Git
Cheat Sheet
Markdown
Tools
C++
Linker
Thread
Linux
TCP
Network
GDB
Debug
leetcode
链表
WSL
Ubuntu
Windows
Linux Kernel
GCC
Android
adb
Troubleshooting
Profiling
Sanitizer
glibc
MySQL
Database
Python
curl
Build
ELF
clang-format
CMake
Graphviz
Performance
vcpkg
Protobuf
排查
速查
内存
STL
调试
性能分析
性能
读书笔记
方法论
架构
网络
Timer
mbedTLS
TLS
安全
负载均衡
脚本
工具
LRU
二叉树
BST
中序遍历
回溯
二分查找
优先队列
排序
旋转数组
jenkins
部署